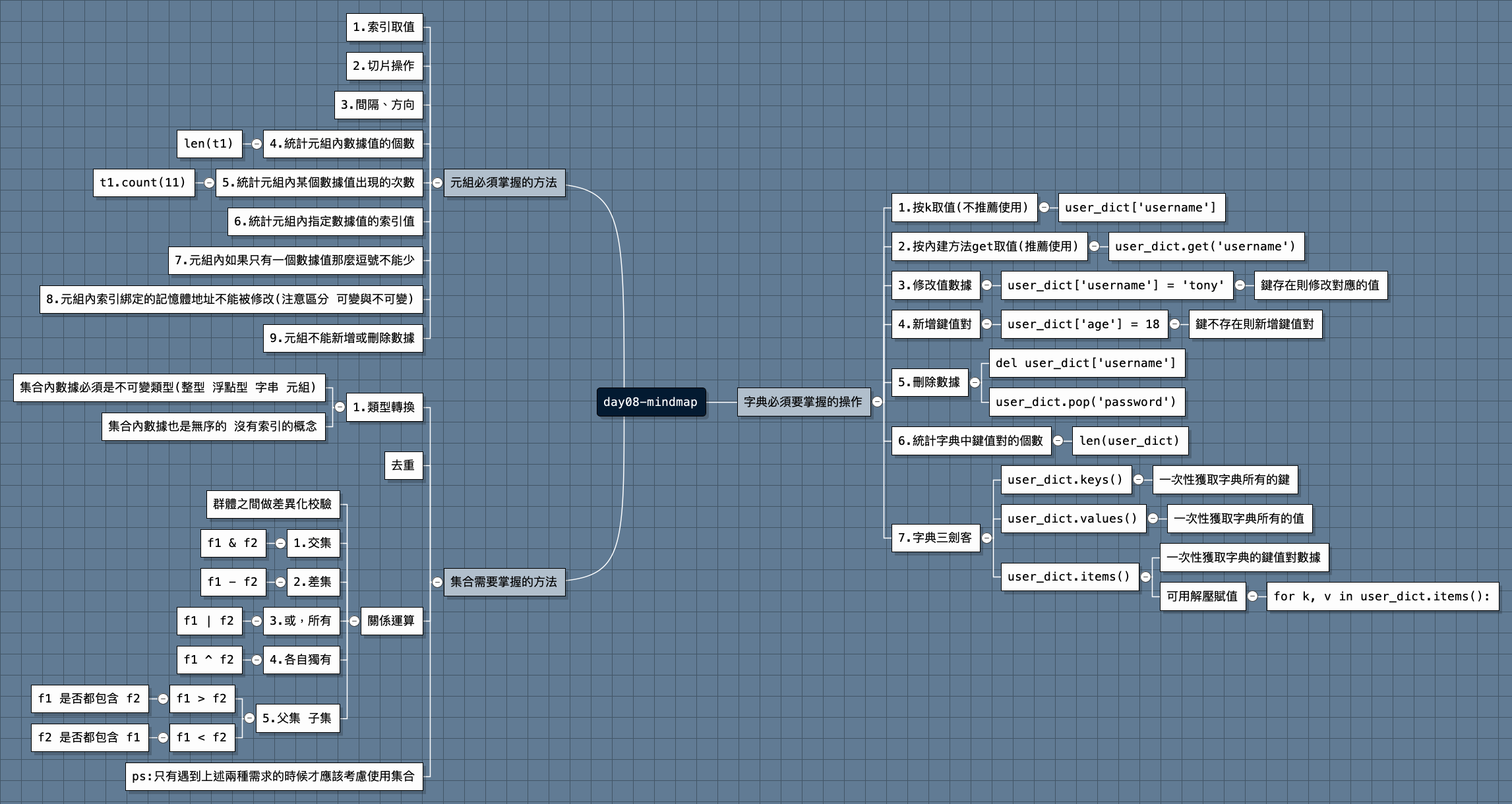
字典相關操作
1.類型轉換
dict()
字典的轉換一般不使用關鍵字 而是自己動手轉
print(dict([('name', 'pwd'), ('jimmy', '123')])) # {'name': 'pwd', 'jimmy': '123'}
2.字典必須要掌握的操作
user_dict = {
'username': 'jimmy',
'password': 123,
'hobby': ['read', 'music', 'run']
}
1.按k取值(不推薦使用)
print(user_dict['username']) # jimmy
print(user_dict['phone']) # k不存在會直接報錯
2.按內建方法get取值(推薦使用)
print(user_dict.get('username')) # jimmy
print(user_dict.get('age')) # None
print(user_dict.get('username', '沒有喲 嘿嘿嘿')) # jimmy 鍵存在的情況下獲取對應的值
print(user_dict.get('phone', '沒有喲 嘿嘿嘿')) # 鍵不存在默認返回None 可以通過第二個參數自訂
3.修改值數據
print(id(user_dict))
user_dict['username'] = 'tony' # 鍵存在則修改對應的值
print(id(user_dict))
print(user_dict)
4.新增鍵值對
user_dict['age'] = 18 # 鍵不存在則新增鍵值對
print(user_dict)
5.刪除數據
del user_dict['username']
print(user_dict) # {'password': 123, 'hobby': ['read', 'music', 'run']}
res = user_dict.pop('password')
print(user_dict) # {'username': 'jimmy', 'hobby': ['read', 'music', 'run']}
print(res) # 123
6.統計字典中鍵值對的個數
print(len(user_dict)) # 3
7.字典三劍客
print(user_dict.keys()) # 一次性獲取字典所有的鍵 dict_keys(['username', 'password', 'hobby'])
print(user_dict.values()) # 一次性獲取字典所有的值 dict_values(['jimmy', 123, ['read', 'music', 'run']])
print(user_dict.items()) # 一次性獲取字典的鍵值對數據 dict_items([('username', 'jimmy'), ('password', 123), ('hobby', ['read', 'music', 'run'])])
for i in user_dict.items():
k, v = i
print(k, v)
8.補充說明
print(dict.fromkeys(['name', 'pwd', 'hobby'], 123)) # 快速生成值相同的字典 # {'name': 123, 'pwd': 123, 'hobby': 123}
res = dict.fromkeys(['name', 'pwd', 'hobby'], [])
print(res) # {'name': [], 'pwd': [], 'hobby': []}
res['name'].append('jimmy')
res['pwd'].append(123)
res['hobby'].append('study')
print(res) # {'name': ['jimmy', 123, 'study'], 'pwd': ['jimmy', 123, 'study'], 'hobby': ['jimmy', 123, 'study']}
'''當第二個公共值是可變類型的時候 一定要注意 通過任何一個鍵修改都會影響所有'''
res = user_dict.setdefault('username','tony')
print(user_dict, res) # 鍵存在則不修改 結果是鍵對應的值 # {'username': 'jimmy', 'password': 123, 'hobby': ['read', 'music', 'run']} jimmy
res = user_dict.setdefault('age',123)
print(user_dict, res) # 存不存在則新增鍵值對 結果是新增的值 # {'username': 'jimmy', 'password': 123, 'hobby': ['read', 'music', 'run'], 'age': 123} 123
user_dict.popitem() # 彈出鍵值對 後進先出
元組相關操作
1.類型轉換
tuple()
ps:支持for循環的數據類型都可以轉成元組
2.元組必須掌握的方法
t1 = (11, 22, 33, 44, 55, 66)
1.索引取值
2.切片操作
3.間隔、方向
4.統計元組內數據值的個數
print(len(t1)) # 6
5.統計元組內某個數據值出現的次數
print(t1.count(11)) # 1
6.統計元組內指定數據值的索引值
print(t1.index(22)) # 1
7.元組內如果只有一個數據值那麼逗號不能少
8.元組內索引綁定的記憶體地址不能被修改(注意區分 可變與不可變)
9.元組不能新增或刪除數據
集合相關操作
1.類型轉換
set()
集合內數據必須是不可變類型(整型 浮點型 字串 元組)
集合內數據也是無序的 沒有索引的概念
2.集合需要掌握的方法
去重
關係運算
ps:只有遇到上述兩種需求的時候才應該考慮使用集合
3.去重
s1 = {11, 22, 11, 22, 22, 11, 222, 11, 22, 33, 22}
print(s1) # {33, 11, 222, 22}
l1 = [11, 22, 33, 22, 11, 22, 33, 22, 11, 22, 33, 22]
s1 = set(l1)
l1 = list(s1)
print(l1) # [33, 11, 22]
'''集合的去重無法保留原先數據的排列順序'''
4.關係運算
群體之間做差異化校驗
eg: 兩個微信帳戶之間 有不同的好友 有相同的好友
f1 = {'jimmy', 'tony', 'jerry', 'oscar'} # 用戶1的好友列表
f2 = {'jack', 'jimmy', 'tom', 'tony'} # 用戶2的好友列表
1.求兩個人的共同好友
print(f1 & f2) # {'jimmy', 'tony'}
2.求用戶1獨有的好友
print(f1 - f2) # {'jerry', 'oscar'}
3.求兩個人所有的好友
print(f1 | f2) # {'jimmy', 'jack', 'tom', 'tony', 'oscar', 'jerry'}
4.求兩個人各自獨有的好友
print(f1 ^ f2) # {'oscar', 'tom', 'jack', 'jerry'}
5.父集 子集
print(f1 > f2) # False # f1 是否都包含 f2
print(f1 < f2) # False # f2 是否都包含 f1
字節編碼理論
該知識點理論特別多 但是結論很少 代碼使用也很短
1.字符編碼只針對文本數據
2.回憶計算機內部儲存數據的本質
3.既然計算機內部只認識01 為什麼我們卻可以敲出人類各式各樣的字節
肯定存在一個數字跟字符的對應關係 儲存該關係的地方稱為>>>:字符編碼本
4.字符編碼發展史
4.1.一家獨大
計算機是由美國人發明的 為了能夠讓計算機識別英文
需要發明一個數字跟英文字母的對應關係
ASCII碼:記錄了英文字母跟數字的對應關係
用8bit(1位元組)來表示一個英文字符
4.2.群雄割據
中國人
GBK碼:記錄了英文、中文與數字的對應關係
用至少16bit(2位元組)來表示一個中文字符
很多生僻字還需要使用更多的位元組
英文還是用8bit(1位元組)來表示
日本人
shift_JIS碼:記錄了英文、日文與數字的對應關係
韓國人
Euc_kr碼:記錄了英文、韓文與數字的對應關係
"""
每個國家的計算機使用的都是自己訂製的編碼本
不同國家的文本數據無法直接交互 會出現"亂碼"
"""
4.3.天下一統
unicode萬國碼
相容所有國家語言字節
起步就是兩個位元組來表示字節
utf系列:utf8 utf16 ...
專門用於最佳化unocide儲存問題
英文還是採用一個位元組 中文三個位元組
字節編碼實操
1.針對亂碼不要慌 切換編碼慢慢試即可
2.編碼與解碼
編碼:將人類的字符按照指定的編碼編碼成計算機能夠讀懂的數據
字串.encode()
info = '假日是用來充實自己 不是用來偷懶的'
info.encode('utf8')
res = info.encode('utf8')
解碼:將計算機能夠讀懂的數據按照指定的編碼解碼成人能夠讀懂
bytes類型數據.decode()
res.decode('utf8')
3.python2與python3差異
python2預設的編碼是ASCII
1.文件頭
# encoding:utf8
# -*- encoding:utf8 -*- =>沒有什麼特別,只是比較好看而已
2.字符串前面加u
u'你好啊'
python3預設的編碼是utf系列(unicode)
作業
1.最佳化員工管理系統
拔高: 是否可以換成字典或者數據的嵌套使用完成更加完善的員工管理而不是簡簡單單的一個使用者名稱(能寫就寫不會沒有關係)
員工的資訊有:使用者名稱 年齡 崗位 薪資...
員工管理系統:註冊、查看(單個員工、所有員工)、修改薪資、刪除員工
2.去重下列列表並保留數據值原來的順序
eg: [1,2,3,2,1] 去重之後 [1,2,3]
l1 = [2,3,2,1,2,3,2,3,4,3,4,3,2,3,5,6,5]
3.有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
pythons={'jimmy','oscar','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即報名python又報名linux課程的學員名字集合
2. 求出所有報名的學生名字集合
3. 求出只報名python課程的學員名字
4. 求出沒有同時這兩門課程的學員名字集合
4.統計列表中每個數據值出現的次數並組織成字典戰士
eg: l1 = ['jimmy','jimmy','kevin','oscar']
結果:{'jimmy':2,'kevin':1,'oscar':1}
真實數據
l1 = ['jimmy','jimmy','kevin','oscar','kevin','tony','kevin']
# 1.最佳化員工管理系統
# STEP2.定義一個儲存所有員工資訊的字典
user_data_dict = {} # {'編號':用戶字典, '編號':用戶字典}
'''
數據儲存的方式1(有點欠缺,沒有辦法很精確判斷值代表什麼)
{
'jimmy':[18, 'teacher', 10],
'kevin':[28, 'sale', 90]
}
數據儲存的方式2(還可以,但是如果key,同時為jimmy的時候,就不能用了)
{
'jimmy':{'age':18, 'job':'teacher', 'salary':8000},
'kevin':{'age':28, 'job':'sale', 'salary':9000}
}
數據儲存的方式3(用編號做字典的鍵,兼容性最好)
{
'1':{'name':'jimmy','age':18, 'job':'teacher', 'salary':8000},
'2':{'name':'kevin','age':28, 'job':'sale', 'salary':9000},
'3':{'name':'jimmy','age':18, 'job':'teacher', 'salary':8000},
}
'''
# STEP1.先搭建系統骨架
while True:
print("""
1.創建員工資訊
2.查看單個員工
3.查看所有員工
4.修改員工薪資
5.刪除員工資訊
""")
choice = input('請選擇您想要執行的功能編號>>>:').strip()
if choice == '1':
while True:
# 1.獲取員工編號
emp_id = input('請輸入該員工的員工編號(q)>>>:').strip()
if emp_id == 'q':
break
# 判斷編號是否是純數字
if not emp_id.isdigit():
print('員工編號必須是純數字')
continue
# 2.判斷員工編號是否已存在
if emp_id in user_data_dict:
print('員工編號已存在 請重新輸入')
continue
# 3.獲取員工詳細資訊
username = input('請輸入員工姓名>>>:').strip()
age = input('請輸入員工年齡>>>:').strip()
job = input('請輸入員工崗位>>>:').strip()
salary = input('請輸入員工薪資>>>:').strip()
# 4.構建一個臨時的小字典
temp_dict = {}
# 5.添加員工資訊鍵值對
temp_dict['emp_id'] = emp_id
temp_dict['name'] = username
temp_dict['age'] = age
temp_dict['job'] = job
temp_dict['salary'] = salary
# 6.添加到大字典中
user_data_dict[emp_id] = temp_dict
print(f'員工{username}添加成功')
elif choice == '2':
while True:
# 1.先獲取員工編號
target_id = input('請輸入您想要查看的員工編號(q)>>>:').strip()
if target_id == 'q':
break
# 2.判斷員工編號是否不存在
if target_id not in user_data_dict:
print('員工編號不存在 無法查看')
continue
# 3.根據員工編號獲取員工字典數據
user_dict = user_data_dict.get(target_id)
# 4.格式化輸出
print(f"""
--------------info of emp-------------------
編號:{user_dict.get('emp_id')}
姓名:{user_dict.get('name')}
年齡:{user_dict.get('age')}
崗位:{user_dict.get('job')}
薪資:{user_dict.get('salary')}
--------------------------------------------
""")
elif choice == '3':
for user_dict in user_data_dict.values():
print(f"""
--------------info of emp-------------------
編號:{user_dict.get('emp_id')}
姓名:{user_dict.get('name')}
年齡:{user_dict.get('age')}
崗位:{user_dict.get('job')}
薪資:{user_dict.get('salary')}
--------------------------------------------
""")
elif choice == '4':
while True:
# 1.先獲取想要修改的員工編號
target_id = input('請輸入您想要修改的員工編號(q)>>>:').strip()
if target_id == 'q':
break
if target_id not in user_data_dict:
print('員工編號不存在')
continue
# 2.獲取新的薪資
new_salary = input('請輸入該員工的新薪資待遇>>>:').strip()
if not new_salary.isdigit():
print('薪資只能是純數字')
continue
# 3.獲取員工字典
user_dict = user_data_dict.get(target_id) # {'salary':123}
# 4.修改字典中的薪資
user_dict['salary'] = new_salary # {'salary': 321}
# 5.修改大字典
user_data_dict[target_id] = user_dict
print(user_data_dict.get(target_id))
elif choice == '5':
while True:
# 1.先獲取想要修改的員工編號
target_id = input('請輸入您想要刪除的員工編號(q)>>>:').strip()
if target_id == 'q':
break
if target_id not in user_data_dict:
print('員工編號不存在')
continue
# 2.字典刪除鍵值對
user_data_dict.pop(target_id)
else:
print('抱歉 暫無該功能編號!!!')
# 2.去重下列列表並保留數據值原來的順序
# eg: [1,2,3,2,1] 去重之後 [1,2,3]
l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
# 不考慮順序的情況下 去重
s1 = set(l1)
l2 = list(s1)
print(l2)
# 考慮順序
new_list = []
for i in l1:
if i not in new_list:
new_list.append(i)
print(new_list)
# 3.有如下兩個集合,pythons是報名python課程的學員名字集合,linuxs是報名linux課程的學員名字集合
# pythons={'jimmy','oscar','kevin','ricky','gangdan','biubiu'}
# linuxs={'kermit','tony','gangdan'}
# 1. 求出即報名python又報名linux課程的學員名字集合
# 2. 求出所有報名的學生名字集合
# 3. 求出只報名python課程的學員名字
# 4. 求出沒有同時這兩門課程的學員名字集合
pythons = {'jimmy', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
print(pythons & linuxs)
print(pythons | linuxs)
print(pythons - linuxs)
print(pythons ^ linuxs)
# 4.統計列表中每個數據值出現的次數並組織成字典展示
# eg: l1 = ['jimmy','jimmy','kevin','oscar']
# 結果:{'jimmy':2,'kevin':1,'oscar':1}
# 真實數據
l1 = ['jimmy', 'jimmy', 'kevin', 'oscar', 'kevin', 'tony', 'kevin']
# 1.先定義結果集空字典
data_dict = {}
# 2.循環列表中每一個數據值
for name in l1: # 'jimmy' 'kevin'
# 3.判斷當前數據值是否在字典的k中
if name not in data_dict: # {'jimmy':1}
data_dict[name] = 1
else:
data_dict[name] += 1
# data_dict[name] = data_dict.get(name) + 1
print(data_dict)